本文为 2019-08-16 提供的专题文稿(未开设讲座),讲解了字符(文本)的计算机表示,以帮助理解软件开发中可能遇到的字符乱码问题。
This post is the objective article provided on 2019-08-16 (no lecture held), which briefly explains the computer representation of characters (texts), in order to help understanding the possible incorrect character encoding/decoding during software development.
任何信息一但涉及给人看或与人交互,其复杂程度就会急剧上升。
——我
以下内容以知乎专栏“刨根究底学编程”的《刨根究底字符编码》系列文章为基础,参考维基百科、Unicode 官方资料等内容,整理、修改、扩充而成。
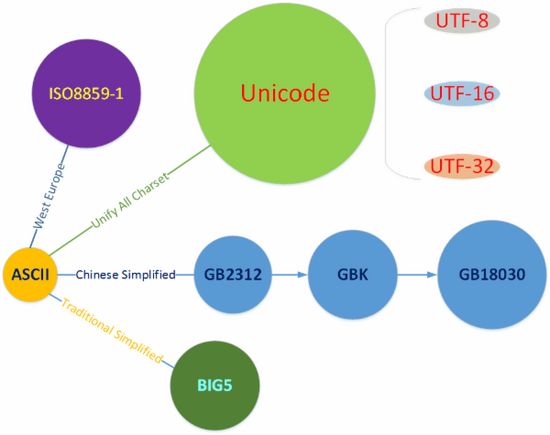
1 基本概念与术语 / Basic concepts, terminology
1.1 基本概念 / Basic concepts
字符(character):文字、数字、字母、音节、标点符号、图形符号等。
| Z | [基本拉丁字母] 拉丁文大写字母 Z | [Basic Latin] Latin Capital Letter Z |
| § | [拉丁文补充1] 节标记 | [Latin-1 Supplement] Section Sign |
| क | [天城文] 天成文书(梵文)字母 Ka | [Devanagari] Devanagari Letter Ka |
| ∲ | [数学运算符] 顺时针围道积分 | [Mathematical Operators] Clockwise Contour Integral |
| ㍿ | [中日韩字符集兼容] 方块字株式会社 | [CJK Compatibility] Square Corporation |
| 沃 | [中日韩统一表意文字] 中日韩象形文字 | [CJK Unified Ideographs] Ideograph water, irrigate; fertile, rich CJK |
| 퀣 | [谚文音节] 谚文音节 Kwelb | [Hangul Syllables] Hangul Syllable Kwelb |
| 𝌍 | [太玄经符号] 表示对立的四符号组合 | [Tai Xuan Jing Symbols] Tetragram for Opposition |
| 🀣 | [麻将牌] 麻将牌 兰花 | [Mahjong Tiles] Mahjong Tile Orchid |
| 🃏 | [扑克牌] 扑克牌 小丑表情符号 | [Playing Cards] Playing Card Black Joker Emoji |
| 𢨋 | [中日韩统一表意文字] | [CJK Unified Ideographs Extension B] |
注:同一符号在不同字体中(在字体支持该符号的情况下)有不同的表现形式(字形)。如,“扑克牌 小丑表情符号”在不同系统(即不同系统的默认字体)中的字形如下:

🗨
Unicode 的“谚文音节”区段共包含 11,172 个字符,是符合谚文组字规律的全部合成字符的集合,其中有大量实际不使用的字符用于输入法展示任何可能出现的字母组合。
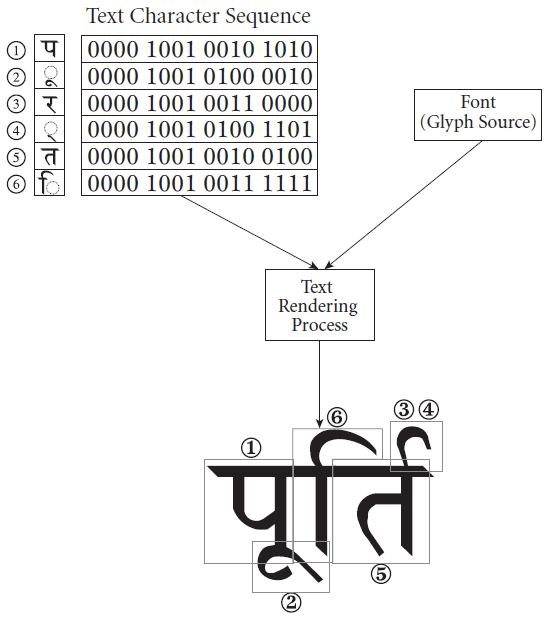
🗨 从字符编码到信息呈现过程的特殊问题:
(1) 文本渲染
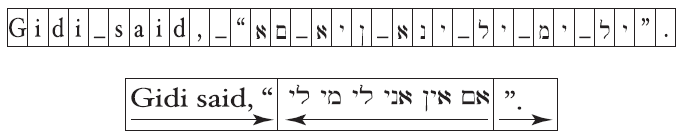
(2) 双向排序
(3) 书写顺序
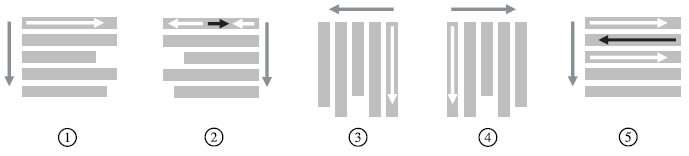
综上,信息的表示可能是非线性的,这是排版系统需注意的重要环节。但编码的信息流是线性的。
字符集(character set, charset):字符的集合。常用字符集有 ASCII、ISO 8859 系列、GB 系列、Unicode 等。
编码(encode)
解码(decode)
字符编码(character encoding):把字符集中的字符按一定方式编码为某个指定集合中的某个对象(如二进制位串、十进制自然数序列、电脉冲等)的过程。
1.2 字符编码模型 / Character encoding model
字符编码模型(Character Encoding Model):反映字符编码系统的结构特点和各构成部分相互关系的模型框架。
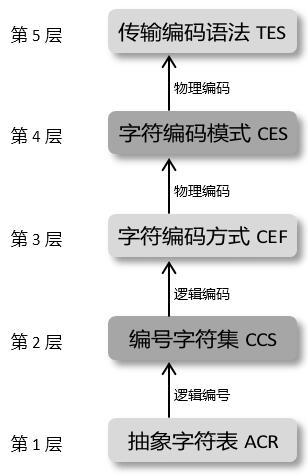
Unicode Technical Report #17(Unicode Character Encoding Model)将现代字符编码模型分为 5 个层次:
- 第1层 抽象字符表 ACR(Abstract Character Repertoire):明确字符的范围(即确定支持哪些字符)
- 第2层 编号字符集 CCS(Coded Character Set):用数字编号表示字符(即用数字给抽象字符表 ACR 中的字符进行编号)
- 第3层 字符编码方式 CEF(Character Encoding Form):将字符编号编码为逻辑上的码元序列(即逻辑字符编码)
- 第4层 字符编码模式 CES(Character Encoding Scheme):将逻辑上的码元序列映射为物理上的字节序列(即物理字符编码)
- 第5层 传输编码语法 TES(Transfer Encoding Syntax):将字节序列作进一步的适应性编码处理
第1层 抽象字符表 ACR
(1) 其中的字符没有编排的顺序。
(2) 抽象字符不具有特定的字形。
望 [字形对比(汉典)](见链接页面的“字源字形”段“字形对比”节,下同)
沿 [字形对比(汉典)]
(3) 字符表可以是封闭的(即字符范围固定),也可以是开放的(即允许不断添加新字符)。
第2层 编号字符集 CCS
将抽象字符表 ACR 中的每个抽象字符表示为一个非负整数或映射到一个坐标(非负整数值对 (x, y)),也就是将抽象字符的集合映射到一个非负整数或非负整数值对的集合,映射的结果就是编号字符集 CCS。
编号空间(code space):根据抽象字符表中抽象字符的数目,可以设定一个字符编号的上下限值(该上限值往往设定为大于抽象字符表中的字符总数),从0到该上限值之间的非负整数范围就称之为编号空间。如:GB 2312 的汉字编号空间是 94×94。
编号空间中的一个位置(position)称为码点(code point)或码位(code position)。一个字符占用的码点所在的坐标或所代表的非负整数就是该字符的编号,又称为码点值。
在 Unicode 编码方案中,字符码点又被称为 Unicode 标量值(Unicode scalar value)。
编号字符集可简单理解为是把抽象字符进行逐个编号或逐个映射为码点值后的结果。编号字符集常简称为字符集。
在 Unicode 标准中,单个抽象字符(特别是汉字)可能与多个码点对应:
(1) 早期的标准中区分了不同的字形,并被后续标准继承。
| U+6236 | 戶 | [中日韩象形文字] Ideograph door; family, household CJK |
| U+6237 | 户 | [中日韩象形文字] Ideograph door; family CJK |
| U+6238 | 戸 | [中日韩象形文字] Ideograph door; family CJK |
(“沪” [字形对比(汉典)] 字等组合汉字的不同字形未区分。)
(2) 与其他标准兼容。
以兼容韩国字符集标准 KS X 1001:1998 为例,该标准给(韩国汉字中的)多音字的每个读音都分配了编码(码位)。
| U+51C9 | 凉 | [中日韩象形文字] Ideograph cool, cold; disheartened CJK | 량 (liang) |
| U+F979 | 凉 | 양 (yang),량的变音 | |
| U+6A02 | 樂 | [中日韩象形文字] Ideograph happy, glad; enjoyable; music CJK | 악 (ag),对应普通话的读音 yuè,表音乐 |
| U+F95C | 樂 | 락 (lag),对应普通话的读音 lè,表快乐 | |
| U+F914 | 樂 | 낙 (nag),락的变音 | |
| U+F9BF | 樂 | 요 (yo),对应普通话的读音 yào,表喜爱 |
第3层 字符编码方式 CEF
将编号字符集里字符的码点值(即字符编号)转换成有限比特长度的编码值(即字符编码)。该编码值实际上是码元的序列(code unit sequence)。
UTF-8、UTF-16 和 UTF-32 是 Unicode 字符集(即编号字符集)常用的字符编码方式。
像 ASCII 这样传统的、简单的字符编码系统,不需要区分字符编号与字符编码,可认为字符编号就是字符编码,两者之间是直接映射的关系。
而在 Unicode 这样现代的、复杂的字符编码系统中,字符编号不一定等于字符编码,如 UTF-8、UTF-16 为间接映射,UTF-32 为直接映射。
第4层 字符编码模式 CES
又称为序列化格式(Serialization Format),指的是将字符编号进行编码之后的码元序列映射为字节序列(即字节流)后的形式,以便经过编码后的字符能在计算机中处理、存储和传输。
通过字符编码方式 CEF 编码后所形成的码元序列,更多的是一种逻辑意义上的中间编码。而通过字符编码模式 CES 将码元序列进一步编码后所形成的字节序列,才是物理意义上的最终编码。
第5层 传输编码语法 TES
由于历史原因,在某些特殊的传输环境中,需要对字符编码模式 CES 所提供的字节序列(字节流)作进一步的适应性编码处理:
(1) 把字节序列映射到一套更受限制的值域内,以满足传输环境的限制。如用于Email 传输的 Base64 编码或 quoted-printable 编码(可打印字符引用编码),把 8 位的字节映射为 7 位长的数据。
(2) 压缩字节序列的值。如 LZW 或进程长度编码等无损压缩技术。
2 字符编码历史 / History of character encodings
2.1 西文字符编码 / Western character encodings
EBCDIC(Extended Binary Coded Decimal Interchange Code,扩展二进制编码的十进制交换码)
由 IBM 为大型机操作系统而开发设计,于1964年推出。
EBCDIC 码表(维基百科)
EBCDIC 存在英文字母不连续的问题。
ASCII(American Standard Code for Information Interchange,美国信息交换标准码)
由美国国家标准学会 ANSI(American National Standard Institute)于1968年正式制定。之后于 1972 年被 ISO/IEC 采用,制定为 ISO/IEC 646 标准。
目前所通行的其他字符编码方案,如 ISO-8859 系列、GB 系列(GB 2312, GBK, GB 18030, GB 13000)、Big5、Unicode 等,均直接或间接兼容 ASCII。
ASCII 使用 7 个二进制位(bit)表示一个字符,共表示 128 个字符。在以 8 位为一个字节进行存取和处理的系统中,最高位为 0,但有时也被用作一些通讯系统的奇偶校验位。
若要把字符序列编码的二进制流写入存储设备,只需将该字符序列中的各个字符在 ASCII 中的字符编号直接以二进制字节写入存储设备即可。字符编号就是字符编码,无需特别的编码算法进行字符编号到字符编码的转换计算,更不存在码元序列到字节序列的转换。
Extended ASCII(扩展 ASCII,EASCII)
将 ASCII 中闲置的最高位用来编码新的字符。
扩充的符号包括表格符号、计算符号、希腊字母和特殊的拉丁符号。
ISO/IEC 8859 字符编码方案
与 EASCII 一样利用 ASCII 未使用的最高位将编码范围从 0x00~0x7F(0~127),扩展到 0x80~0xFF(128~255)。实际上只使用了 0xA0~0xFF(160~255)共 96 个编码。
ISO/IEC 8859 是一组字符集的总称,其下共有 15 个字符集(1~11, 13~16),大致上包括了欧洲各国所使用的字符(和一些外来语字符)。其中,ISO/IEC 8859-1 收录了西欧常用字符(包括德法两国的字母),目前使用最为普遍,别名为 Latin-1。
2.2 中文字符编码 / Chinese character encodings
2.2.1 GB 系列编码 / GB standards
GB 2312(常用字)→ GBK(扩展)→ GB18030(兼容 Unicode,变长字节)
GB 2312–80
《信息交换用汉字编码字符集·基本集》,由中国国家标准总局发布,1981年5月1日实施。共收录 6763 个汉字,其中一级汉字 3755 个,二级汉字 3008 个;同时收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个字符。每个字符使用 2 个 8 位字节表示,并兼容 ASCII 字符。
在一段文本中,如果一个字节是 0~127,其含义同 ASCII 编码;否则,该字节和下一个字节(两个字节的最高位均为 1)共同组成汉字(或是 GB 编码定义的其他字符)。
GB 13000
为便于多文种同时处理,国际标准化组织下属编码字符集工作组制定了 ISO/IEC 10646.1:1993,收录了 20 902 个字符,含陆、台、日、韩汉字。随后,中国制定了与之对应的国家标准:GB13000.1-1993《信息技术 通用多八位编码字符集(UCS)第一部分:体系结构与基本多文种平面》。
GBK
《汉字内码扩展规范(GBK)》1.0版
利用 GB2312-1980 未使用的码点空间,收录 GB13000.1-1993 的全部字符,于1995年发布。
GB 2312 中字符的编码所占两个字节的最高位均为 1;GBK 中字符的编码中,第一个字节的最高位为 1,第二个字节最高位可以是 0 或 1。
GBK 的编码范围(维基百科)
GBK/1 收录除 GB 2312 符号外的增补符号,GBK/2 收录 GB 2312 汉字,GBK/3 收录 CJK 汉字,GBK/4 收录 CJK 汉字和增补汉字,GBK/5 为非中文字符集,UDC 为用户自定义字符区。
以上 GB 类字符集(非 ASCII 部分)属双字节字符集(Double Byte Character Set, DBCS)。基于 DBCS 的编码方案最大的特点是双字节的中文字符和单字节长的 ASCII 字符完全兼容,可并存于同一个文件内。
🗨 微软的 CP 936 字码表(即代码页 936,Code Page 936)一开始等同于 GB 2312-1980,自 Windows 95 起采用 GBK 编码,但缺少 95 个字符(80 个汉字和 15 个非汉字)。
GB 18030
《信息技术 信息交换用汉字编码字符集 基本集的扩充》
GB 18030-2000 除保留全部 GBK 编码汉字外,在第二字节再度进行扩展,增加了大约一百个汉字,在四位元组编码空间增加了 CJK 中日韩统一表意文字扩充 A 中的汉字。GB 18030-2005 增加了 CJK 中日韩统一表意文字扩充 B 中的汉字。
🗨 微软的 CP 54936 对应 GB 18030,但实际上并未使用。
2.2.2 大五码 / Big5
台湾等地区的业界标准。
🗨 中文简繁体
繁体中文存在多个标准,中国大陆地区、台湾地区、港澳地区和马(来西亚)新(加坡)地区使用的繁体中文(或称国字)的字符和字形不完全一致。如,“为”字对应的繁体中文标准字符,在中国大陆为“爲”,在港台为“為”;“说”字对应的繁体中文标准字形,在陆港为“説”,在台湾为“說”。
马新地区使用的中文为简体字。新加坡自 1976 年起,使用的简体字与中国大陆的《简化字总表》一致。马来西亚现行简体字标准与中国大陆不同:部分汉字的简化方式不同,部分汉字等同于二简字。
2.2.3 中日韩统一表意文字 / CJK Unified Ideographs
又称“统一汉字”(Unihan),目的是要把分别来自中文(包含壮文)、日文、韩文、越文中,起源相同、本义相同、形状一样或稍异的表意文字在 Unicode 标准及 ISO/IEC 10646 标准中赋予相同的码点值。
所谓“起源相同、本义相同、形状一样或稍异的表意文字”,主要为汉字,包括繁体字、简化字、日本汉字、韩国汉字、琉球汉字、越南的喃字与儒字、方块壮字。
2.3 ANSI 编码 / ANSI encodings
各个国家和地区所独立制定的、兼容 ASCII 又互不兼容的字符编码,微软统称为 ANSI 编码。(ANSI 的本意为美国国家标准学会(American National Standards Institute)。)Windows 操作系统在没有使用 UTF-16 之前(Windows NT 之前),定义了一系列支持不同国家和地区所制定的兼容 ASCII 的字符编码方案的代码页(Code Page),称为“Windows 代码页”或“ANSI 代码页”。
在 ANSI 编码中,简体中文 GB 编码的代码页是 936,所以 GB 编码又称 ANSI Code Page 936。CP 1252 对应 Latin-1(ISO 8859-1),CP 65001 对应 UTF-8。
查看/修改代码页:
(1) cmd > chcp;
(2) 控制面板→时钟和区域→区域→管理→非 Unicode 程序的语言→更改系统区域设置(C)…
代码页是字符集的具体实现,可以将其理解为一张“字符—字节”映射表,通过查表实现从字符到字节的翻译。
🗨 对二进制信息按不同编码方式解码的示例:
| 字节 | 0x50 | 0x53 | 0x53 | 0xAE, 0x45 | 0x20 | 0x33 | 0x32 |
| Latin-1 | P | S | S | ®, E | (空格) | 3 | 2 |
| GBK | P | S | S | 瓻 | (空格) | 3 | 2 |
2.4 Unicode 字符集 / Unicode
由多语言软件制造商组成的统一码联盟(The Unicode Consortium)于 1991 年发布了统一码标准(The Unicode Standard),定义了全球统一的通用字符集。
ISO/IEC 于 1993 年联合发布了通用多八位组编号字符集(Universal Multiple-Octet Coded Character Set,习惯译为“通用多八位编码字符集”),简称 UCS(Universal Character Set,通用字符集),标准号为 ISO/IEC 10646-1。
自 Unicode 2.0 起,Unicode 字符集和 UCS 字符集基本保持了一致。
目前,Unicode 字符集将所有字符按照使用上的频繁度划分为 17 个平面(plane),每个平面的编号空间有 216 = 65 536 个码点。
基本平面(Basic Plane,BP)
0 号平面:BMP(Basic Multilingual Plane,基本多文种平面),基本涵盖了当今世界上正在使用的常用字符。
补充平面(Supplementary Plane,SP)
1 号平面:SMP(Supplementary Multilingual Plane,多文种补充平面),包括历史上出现的文字符号(如埃及象形文字)以及特定领域的符号和记号(如表情符号、多米诺骨牌)。
2 号平面:SIP(Supplementary Ideographic Plane,表意文字补充平面),用于前述平面未收录的中日韩表意文字,主要是中日韩统一表意文字(CJK Unified Ideographs)。
3 号平面:TIP(Tertiary Ideographic Plane,表意文字第三平面),未正式使用。
4 号 ~13 号平面:尚未使用。
14 号平面:SSP(Supplementary Special-purpose Plane,特别用途补充平面)。
15 号平面:PUA-A(Private Use Area-A,私人使用区(A区))。
16 号平面:PUA-B(Private Use Area-B,私人使用区(B区))。
BMP 有一个专用区(Private Use Zone),0xE000~0xF8FF(57,344~63,743),共 6400 个码点,不会分配给任何字符;还有一个代理区(Surrogate Zone),0xD800-0xDFFF(55,296~57,343),共 2048 个码点,目的是用 BMP 中的两个码点“代理”表示 SIP 的字符(在 UTF-16 编码中使用)。
| 码点(码位) | 字形示例 | 字符含义 | 所属区块 |
|---|---|---|---|
| U+6C38 | 永 | Ideograph long, perpetual, eternal, forever CJK | 中日韩统一表意文字 CJK Unified Ideographs |
起初,Unicode 规定其字符集的编码方式采用两个字节的码元(即 UTF-16 编码方式)。ASCII 字符(和 Latin-1 字符)虽编号不变,但编码需扩展至 16 位。为保持与 ASCII(和 Latin-1)的完全兼容,后来又设计了 UTF-8 编码方式。
🗨 Unicode 仍未区分左/右单/双引号的全角符号和半角符号,这四个字符的实际呈现形式依赖于字体的实现(或排版系统对该字符所属语言的判断)。
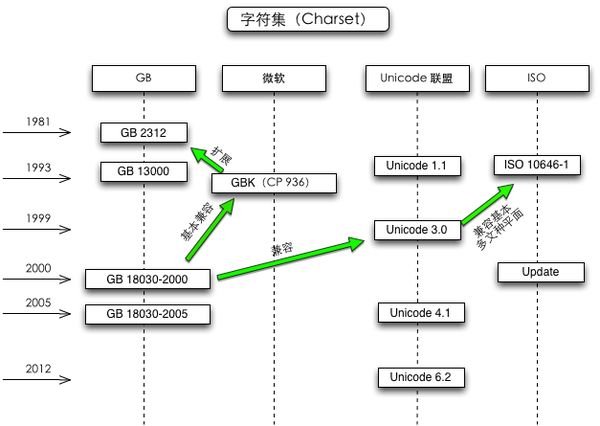
(图中 GBK 与微软 CP 936 的关系有误,见此前的说明。)
注:GBK 字符与相应的 Unicode 字符的码位没有对应关系,只能通过查表的方式转换;GB 18030 为兼容 GBK 和 Unicode,字符的映射关系复杂,仍需通过查表进行编码转换。
3 字符编码方案 / Character encoding schemes
3.1 字符编码基本概念 / Basic concepts of character encoding
对于 ASCII、GBK 等传统字符编码模型,一个字符集只使用一种编码方式。但对于 Unicode 等现代字符编码模型,可以采用多种编码方式。如,Unicode 字符集的编码方式(UTF, Unicode/UCS Transformation Format)有 UTF-8, UTF-16, UTF-32 等。
对于多字节的数据,需指定字节序列(byte sequence),一般称字节序(byte order 或 endianness)。
大端序(BE, big-endian),高尾端序:内存地址的高位存储低字节(尾端)信息。
小端序(LE, little-endian),低尾端序:内存地址的低位存储低字节(尾端)信息。
中间序(ME, middle-endian),混合序。
网络字节序(network byte order)。
| 数据 (首→尾) | 大端序时的内存信息 (低→高) | 小端序时的内存信息 (低→高) |
| 0x1234 | 0x12, 0x34 | 0x34, 0x12 |

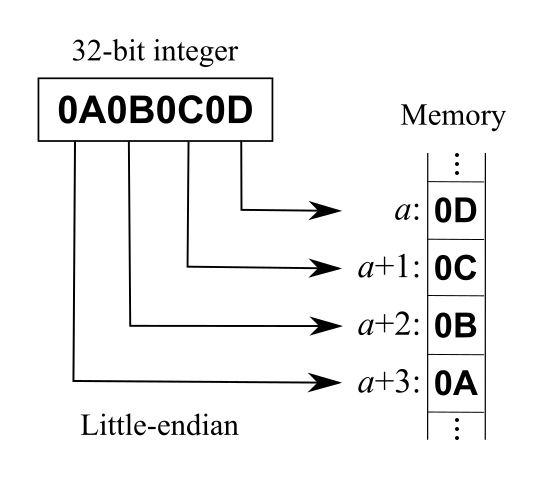
Intel 和 AMD 的 x86 平台采用小端序,IBM、Sun 的 SPARC 采用大端序;ARM, SPARC V9, MIPS 等可切换字节序(称为 bi-endian)。
Windows, FreeBSD, Linux 采用小端序;Mac OS 采用大端序。
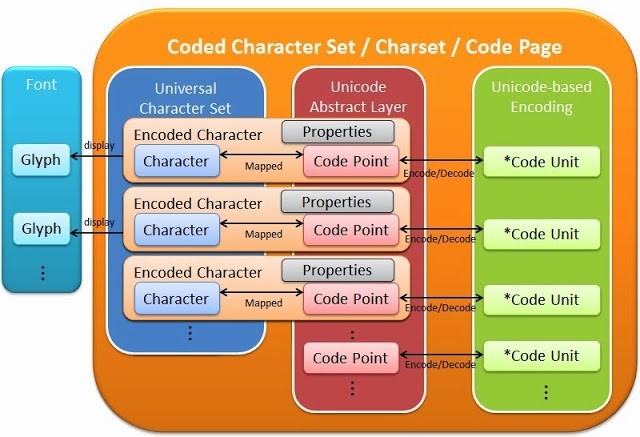
码点(code point)或码位(code position)是字符集编号空间(code space)的一个坐标,字符集中的一个字符对应一个码点。
在计算机存储和网络传输时,码点值(字符编号)被映射到一个或多个码元(code unit)。码元可理解为字符编码方式(CEF)对码点值进行编码处理时作为一个整体来看待的基本单元。类似于基础数据类型中的 byte / word / dword,码元也有单字节和多字节之分。
3.2 UTF
对于 Unicode 字符集,采用不同的码元即对应了不同的 UTF 编码方式:
- UTF-8:Unicode/UCS Transformation Format in 8 bits
- UTF-16:Unicode/UCS Transformation Format in 16 bits
- UTF -32:Unicode/UCS Transformation Format in 32 bits
Unicode 字符码元序列示例:
| 码点 | 字形 | 含义 | UTF-8 | UTF-16 | UTF-32 |
|---|---|---|---|---|---|
| U+004D | M | [基本拉丁字母] 拉丁文大写字母 M | 4D | 004D | 0000004D |
| U+0430 | a | [西里尔字母] 西里尔文小写字母 A | D0 B0 | 0430 | 00000430 |
| U+4E8C | 二 | [中日韩统一表意文字] Ideograph two; twice CJK | E4 BA 8C | 4E8C | 00004E8C |
| U+10302 | 𐌂 | [Old Italic] Old Italic Letter Ke | F0 90 8C 82 | D800 DF02 | 00010302 |
3.2.1 UTF-8
使用一至四个 8 位单字节码元的序列表示 Unicode 字符。
| 占用字节 | 码点可用倍数 | 起始码点 | 末尾码点 | 字节1 | 字节2 | 字节3 | 字节4 |
|---|---|---|---|---|---|---|---|
| 1 | 7 | U+0000 | U+007F | 0xxxxxxx | |||
| 2 | 11 | U+0080 | U+07FF | 110xxxxx | 10xxxxxx | ||
| 3 | 16 | U+0800 | U+FFFF | 1110xxxx | 10xxxxxx | 10xxxxxx | |
| 4 | 21 | U+10000 | U+10FFFF | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
字符举例:永
↓
码点:U+6C38
↓
码点的二进制形式:0110 1100 0011 1000
↓ (需占用 3 个字节)
UTF-8 编码二进制形式:1110 0110 1011 0000 1011 1000
↓
UTF-8 编码:E6 B0 B8
优点:
(1) UTF-8 码元序列的第一个字节即指明了后面所跟的字节数(即 UTF-8 带有前缀码)。
(2) 容错性好,不会因传输过程中的局部错误导致后续字符全部错乱。
(3) 从 UTF-8 字节流的任意位置开始可以有效地找到一个字符的起始位置,字符边界容易检测。
(4) UTF-8 与字节序无关。
缺点:
(1) 作为变长编码方式,无法根据字符数直接判断字节数,反之亦然。因此,计算字符数和执行索引操作的效率不高。
(2) 以 8 位单字节码元编码,无法用于被设计为传输 7 位 ASCII 字符的 E-mail 服务。(由此产生了 UTF-7 编码。)
(3) 实际使用中大量出现 100x xxxx,而 0xC1 在部分字符编码系统中为控制码。(由此产生了 UTF-7.5 编码。)
🗨 在实际应用中,变长编码常用于存储,定长编码常用于程序中的字符串处理。
❕ 字节序标记(BOM)
对于 UTF-16、UTF-32 等采用多字节码元的编码方式,须使用 0xFEFF 指定字节序(byte-order),或称为端序(endianness)。该字符被称为字节序标记(BOM,byte order mark)。
对于 UTF-16 编码的字节流,若开头为 0xFE 0xFF,则表示大端序;若开头为 0xFF 0xFE,则表示小端序。 对于 UTF-32 编码的字节流,若开头为 0x00 0x00 0xFE 0xFF,则表示大端序;若开头为 0xFF 0xFE 0x00 0x00,则表示小端序。若字节流的开头为 0xEF 0xBB 0xBF,则明确说明其为 UTF-8 编码。若未检测到 BOM,则需要文本处理程序根据字节流猜测,或假定其使用事先约定的编码。
最初,如果字符 U+FEFF 出现在字节流的开头,则用来标识该字节流的字节序;如果它出现在字节流的中间,则表示其原义:零宽不折行空格(Zero Width No-Break Space)。该字符是不可见也不可打印的字符。
从 Unicode 3.2 开始,U+FEFF 只能出现在字节流的开头,只用于标识字节序。另使用 U+2060 表示零宽不折行空格。
🗨 Windows Notepad 保存文件时的编码选项中的 UTF-8 长期以来默认为 UTF-8 with BOM。自 Windows 10 1903 起,Notepad 保存文件时的默认编码为 UTF-8 且表示 UTF-8 without BOM,另有 UTF-8 with BOM 可选。
🗨 Windows Notepad 中的“联通”:
| 字符 | 联通 |
| GBK 编码 | 0xC1AA 0xCDA8 |
| 二进制形式 | 1100 0001 1010 1010 1100 1101 1010 1000 |
| 按 UTF-8 w/o BOM 解读 | 1100 0001 1010 1010 1100 1101 1010 1000 |
| Unicode 字符 | U+006A (小于 U+007F) U+0368 |
对于 GBK 编码的文本,若其中的每个字符均满足“第一个字节位于 0xC0~0xDF,第二个字节位于 0x80~0xBF”,这样的文本就可能会被文本编辑器判定为 UTF-8 w/o BOM 编码,并解读为错误的信息。(但较新的 Windows 操作系统中的 Notepad 还会考虑相应字符是否存在,因此“联通”已不会被识别错误。)
3.2.2 UTF-16
源于 UCS-2(2-byte Universal Character Set)。
UCS- 2 将字符编号直接映射为字符编码(CEF),字符编号就是字符编码,中间没有经过特别的编码算法转换。在 Unicode 字符集和 UCS 字符集逐渐融合后,为支持编号超过 U+FFFF 的增补字符,UCS 提出了 UCS-4(使用 4 个字节表示一个字符);而 Unicode 2.0 设计了 UTF-16 编码方式,通过代理机制实现了对这些字符的扩展。
在 UTF-16 中,编号字符集(CCS)中的字符编号与字符编码方式(CEF)中的字符编码不是直接映射关系。
Unicode 字符集基本平面(BMP)中的字符(大致相当于 UCS-2 字符)(除 U+D800~U+DFFF 代理码点部分)仍然是直接映射关系,增补平面(SP)中的字符(大致相当于 UCS-4 字符)需要通过代理机制进行转换。
UTF-16 是变长编码方式,每个字符编码为 16 位或 32 位;UCS-2 是定长编码方式,每个字符编码固定为 16 位。但两者的码元都是 16 位。
除去 UCS-2 所编码的字符集中对应 Unicode 代理码点的部分,UTF-16 所编码的字符集可看作 UCS-2 所编码的字符集的父集。在未引入增补平面字符之前,UTF-16 与 UCS-2(除代理码点部分)的编码完全相同。但由于 UCS-2 编码只使用两个字节,其根本无法编码增补平面的字符)。
🗨 Windows 2000 及之后的版本支持 UTF-16,之前的 Windows NT/95/98/ME 只支持 UCS-2。
🗨 Windows Notepad 保存文件时的编码选项中的 Unicode 长期以来表示 UTF-16 LE,另有 Unicode big endian 表示 UTF-16 BE。自 Windows 10 1903 起,Notepad 保存文件时的编码可选 UTF-16 LE 和 UTF-16 BE。
UTF-16 的出现早于 UTF-8 和 UTF-32。它使用变长码元序列的编码方式,相较于定长码元序列的 UTF-32,算法更复杂,代理机制的使用也使其算法比 UTF-8 复杂。在实际使用中,它会占用过多字节,相较于 UTF-8 更浪费空间和带宽。
代理(surrogate)是专属于 UTF-16 的机制。代理机制使用基本平面(BMP)代理区(Surrogate Zone)中的两个 16 位码元表示增补平面的码点,这两个特殊的 16 位码元被称为“代理对”(surrogate pair)。为避免冲突,被用作代理的任一码元所对应的码点在基本平面中均未指定字符。
增补平面一共有 16 个平面(平面 2~17),码点编号范围为 0x1 0000~0x10 FFFF(65,536~1,114,111,码点总数为 1,048,576 个)。用两个代理码元表示时,第一个码元的取值范围为 0xD800~0xDBFF(55,296~56,319),第二个码元的取值范围为 0xDC00~0xDFFF(56,320~57,343)。
| 高位代理/引导代理 (lead surrogate) | 低位代理/尾随代理 (trail surrogate) |
| 1101 10pp ppxx xxxx (0xD800 + 高 10 位) | 1101 11xx xxxx xxxx (0xDC00 + 低 10 位) |
其中,pppp 表示增补平面的序号(从 0 开始),16 位的 x 表示在该增补平面内的码点。
字符举例:🀣
↓
码点:U+1 F023
↓ 使用相对于增补平面起始码点(U+1 0000)的偏移量
偏移量:0xF023
↓ 按 20 位比特组分成两部分
高位:00 0011 1100 (0x003C)
低位:00 0010 0011 (0x0023)
↓ 分别计算代理码元
引导代理:0xD800 + 0x003C = 0xD83C
尾随代理:0xDC00 + 0x0023 = 0xDC23
↓
UTF-16 编码:0xD83C DC23
(BE: D8 3C DC 23; LE: 3C D8 23 DC)
UTF-8 / UTF-16 具有:
- 自同步性(self-synchronizing)。由于引导代理、尾随代理、BMP 字符码元三者互不重叠,在 UTF-16 数据流中仅检查一个码元就可以判断当前字符的下一个字符的起始码元,每个字符码元的边界很明确。
- 非传递性。UTF-16 编码的字节流中某个字节出错时,只影响当前字符,不会传递到文本的其他部分。因此,即使文本中某些字符数据遭到破坏,其影响也是局部性的。
许多早期的编码方式(如 GBK 等)不是自同步的,必须从头开始分析文本才能确定不同字符的码元的边界;也不具有非传递性,局部字符数据被破坏时,很可能一直向后传递,导致整个文件无法正确显示。
注:在 UCS-2 中,U+D800~U+DFFF 有字符定义。不过只要不是恰好构成了代理对,还是可以把这些不匹配 Unicode 标准的字符码元正确地辨识、转换成合规的码元。这种因历史原因而出现的码元序列在现在的 Unicode 标准中应视为编码错误。
3.2.3 UTF-32
起初,ISO 10646 定义了 32 位的编码,称为 UCS-4。自 Unicode 3.0 起,UTF-32 可表示全部 UCS 码点,且与 UCS-4 能表示的字符是相同的。
UTF-32 编码长度固定,每 32 位值代表一个 Unicode 字符,且与其所在的码位的值一致。由于 Unicode 字符集最后一个平面的最后一个码位为 0x10FFFF,目前实际可能使用 21 个比特位,所以 UTF-32 编码的前 11 位均为零。
在 UTF-32 编码的文本序列中,字符的位置可以直接使用整数索引定位,而无需像变长字节编码那样按顺序查找到第 n 个字符位置。
由于非 BMP 字符在实际文本中出现的机率极底,使用 UTF-32 会浪费更多空间。
UTF-32 编码的字节流中某个字节出错时,将无法判断下一个字符的起始字节,其影响是全局性的。
3.3 参考资料 / References
Character encoding – Wikipedia
4 补充资料 / Supplementaries
字符映射表:charmap.exe(推荐使用 Windows 10 之前的系统中自带的 Arial Unicode MS 字体查看字符。)
Unicode Character Table:Unicode 字符查询(按区块)
Unicode Standard:Unicode 标准最新版
ICU (International Components for Unicode): a mature, widely used set of C/C++ and Java libraries providing Unicode and Globalization support for software applications.
Leave a Reply